With twenty years in networking, I’ve seen how the calmest networks can hide the wildest problems. Just because everything looks smooth does not mean trouble isn’t brewing beneath the surface.
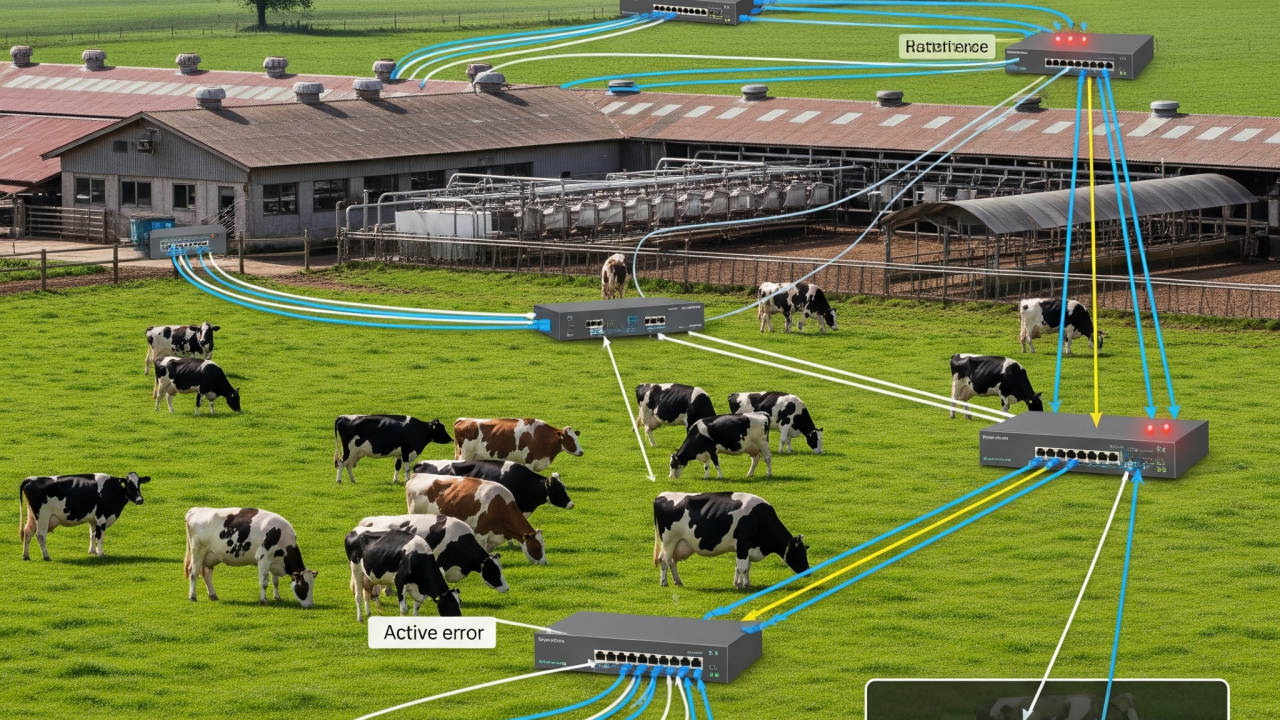
About a year ago, I was called to a large dairy plant facing a problem that was much more than a nuisance. Every so often, certain buckets of the MCC (Motor Control Center) and all their connected gear would simply vanish from the network. When this happened, it did not just interrupt operations. It shut down production entirely, causing major losses and requiring frantic manual intervention to keep things moving. To make matters worse, these incidents almost always happened on nights and weekends, when support was thin and the stakes were high.
On the surface, the network seemed as steady as Dr. Jekyll: calm, predictable, and quietly doing its job. But out of nowhere, usually when everyone was at home or off the clock, a different side would emerge. Segments dropped offline, alarms sounded, and the production line ground to a halt. Then, just as suddenly, everything would return to normal. This left everyone scratching their heads and dreading the next incident.
A Blind Spot: No Logs, No Clues
One of the biggest challenges was the lack of historical logs. The switches were not set up to store logs persistently, so every reboot wiped the slate clean. There was also no centralized log collection. Even though the critical spanning tree events were being logged in real time, they disappeared before anyone could see them. No one noticed the root cause until I arrived on site and started manually digging through what little was left in memory.
Tracking Down the Hidden Problem
Years of experience taught me to look for subtle patterns. Eventually, I traced the outages to a spanning tree protocol mismatch. The Cisco Catalyst distribution switches were running MSTP, while the Stratix 5200 access switches were using PVST+. Most days, this mismatch lay dormant. However, when someone plugged in a laptop running virtualization software that broadcast its own BPDUs, or when a topology change occurred, the Cisco switch would take over as root. The Stratix switches, seeing an unfamiliar BPDU, would lock down and cut off entire MCC sections until things settled down. Production stopped, losses mounted, and someone had to drop everything to fix it, almost always at the worst possible time.
Restoring Order
Once the diagnosis was clear, the solution was straightforward. I brought the switch configurations into alignment, making sure both sides spoke the same protocol and followed best practices. I also identified and fixed several other potential issues in their setup. Afterward, production outages stopped. The network returned to a reliable, stable state and the plant could finally operate smoothly.
The Bigger Lesson: You Can’t Fix What You Can’t See
There is a deeper lesson here. Networks today are too complex and too dynamic to be managed by memory, luck, or “set and forget” strategies.
No logs mean no history and no context. If logging isn't persistent and centralized, you are flying blind. Problems that could be solved in minutes can take days to unravel.
The days of truly deterministic network design are fading. As networks become more flexible and interconnected, perfect predictability is no longer realistic. You cannot always foresee every interaction or edge case.
Continuous monitoring is now essential. Real-time visibility, historical context, and proactive alerting are basic requirements for any production environment.
Lessons Learned
After years in the field, a few big themes stand out.
- Don’t trust a quiet network. Just because it’s working does not mean it’s bulletproof.
- Assume nothing.Even the best equipment can clash if the fine print or default configuration does not match.
- Change is the real test. Most issues appear during transitions, not steady-state, and they tend to happen at the most inconvenient times.
- Document and review, always. A clear map and regular audits catch problems before they catch you.
- Curiosity and monitoring are your best tools. Simulate failures, test the unusual cases, and put systems in place to alert you before small problems become disasters.
Closing Thoughts
Every industrial network has its share of hidden challenges. With modern, dynamic networks, the only way to stay ahead of the next surprise is continuous monitoring, centralized logging, and an eye for the currents beneath the surface.
If your network only breaks at 2am on a Sunday, you are not alone. If you have your own story of tracking down the unexpected, let’s connect and share notes. There are always more lessons to learn.